 Entrada
EntradaEl concepto de confiabilidad estadística. Nivel de confianza estadística
Consideremos un ejemplo típico de la aplicación de métodos estadísticos en medicina. Los creadores del fármaco sugieren que aumenta la diuresis en proporción a la dosis tomada. Para probar esta hipótesis, administran a cinco voluntarios diferentes dosis del fármaco.
Según los resultados de la observación, se traza una gráfica de diuresis versus dosis (fig. 1.2A). La dependencia es visible a simple vista. Los investigadores se felicitan unos a otros por el descubrimiento y al mundo por el nuevo diurético.
De hecho, los datos sólo nos permiten afirmar de forma fiable que se observó una diuresis dosis-dependiente en estos cinco voluntarios. El hecho de que esta dependencia se manifestará en todas las personas que toman el medicamento no es más que una suposición.
zy

 Con
Con
vida No se puede decir que sea infundado; de lo contrario, ¿por qué realizar experimentos?
Pero la droga salió a la venta. Todo mas gente tomarlo con la esperanza de aumentar su producción de orina. Entonces, ¿qué vemos? Vemos la Figura 1.2B, que indica la ausencia de cualquier conexión entre la dosis del fármaco y la diuresis. Los círculos negros indican datos del estudio original. La estadística tiene métodos que nos permiten estimar la probabilidad de obtener una muestra tan “poco representativa” y, de hecho, confusa. Resulta que, en ausencia de una conexión entre la diuresis y la dosis del fármaco, la “dependencia” resultante se observaría en aproximadamente 5 de cada 1000 experimentos. Entonces, en este caso, los investigadores simplemente no tuvieron suerte. Si hubieran usado incluso los más avanzados métodos estadísticos, todavía no los salvaría de cometer un error.
Hemos dado este ejemplo ficticio, pero nada alejado de la realidad, para no señalar la inutilidad.
ness de las estadísticas. Habla de otra cosa, del carácter probabilístico de sus conclusiones. Como resultado de aplicar el método estadístico, no obtenemos la verdad última, sino sólo una estimación de la probabilidad de un supuesto particular. Además, cada método estadístico se basa en su propio modelo matemático y sus resultados son correctos en la medida en que dicho modelo se corresponda con la realidad.
Más sobre el tema CONFIABILIDAD Y SIGNIFICADO ESTADÍSTICO:
- Diferencias estadísticamente significativas en los indicadores de calidad de vida.
- Población estadística. Características contables. El concepto de investigación continua y selectiva. Requisitos para datos estadísticos y el uso de documentos contables y de presentación de informes.
- ABSTRACTO. ESTUDIO DE CONFIABILIDAD DE LAS INDICACIONES DE TONÓMETRO PARA MEDIR LA PRESIÓN INTRAOCULAR A TRAVÉS DEL PÁRPADO 2018, 2018
Si no actúa, la sala no servirá de nada. (Shota Rustaveli)
Términos y conceptos básicos de estadística médica.
En este artículo presentaremos algunos conceptos estadísticos clave que son relevantes al realizar investigaciones médicas. Los términos se analizan con más detalle en los artículos pertinentes.
Variación
Definición. El grado de dispersión de los datos (valores de atributos) en el rango de valores.
Probabilidad
Definición. La probabilidad es el grado de posibilidad de que ocurra un determinado evento bajo ciertas condiciones.
Ejemplo. Expliquemos la definición del término en la frase "La probabilidad de recuperación cuando se usa el medicamento Arimidex es del 70%". El evento es "recuperación del paciente", la condición "el paciente toma Arimidex", el grado de posibilidad es del 70% (en términos generales, de 100 personas que toman Arimidex, 70 se recuperan).
Probabilidad acumulada
Definición. La probabilidad acumulada de sobrevivir en el momento t es la misma que la proporción de pacientes vivos en ese momento.
Ejemplo. Si decimos que la probabilidad acumulada de supervivencia después de un tratamiento de cinco años es 0,7, esto significa que del grupo de pacientes considerado, el 70% del número inicial permaneció vivo y el 30% murió. Es decir, de cada cien personas, 30 murieron en los primeros cinco años.
Tiempo antes del evento
Definición. El tiempo antes de un evento es el tiempo, expresado en algunas unidades, que ha transcurrido desde algún punto inicial en el tiempo hasta que ocurre algún evento.
Explicación. Las unidades de tiempo en la investigación médica son días, meses y años.
Ejemplos típicos de tiempos iniciales:
comenzar a monitorear al paciente
tratamiento quirúrgico
Ejemplos típicos de los eventos considerados:
progresión de la enfermedad
ocurrencia de recaída
muerte del paciente
Muestra
Definición. La porción de una población obtenida por selección.
Con base en los resultados del análisis de la muestra, se extraen conclusiones sobre toda la población, lo cual es válido solo si la selección fue aleatoria. Dado que es prácticamente imposible realizar una selección aleatoria de una población, se deben hacer esfuerzos para garantizar que la muestra sea al menos representativa de la población.
Muestras dependientes e independientes.
Definición. Muestras en las que los sujetos del estudio fueron reclutados de forma independiente unos de otros. Una alternativa a las muestras independientes son las muestras dependientes (conectadas, emparejadas).
Hipótesis
Hipótesis bilaterales y unilaterales.
Primero, expliquemos el uso del término hipótesis en estadística.
El propósito de la mayoría de las investigaciones es probar la veracidad de alguna afirmación. El propósito de las pruebas de drogas suele ser probar la hipótesis de que un medicamento es más eficaz que otro (por ejemplo, Arimidex es más eficaz que el tamoxifeno).
Para garantizar el rigor del estudio, la afirmación que se verifica se expresa matemáticamente. Por ejemplo, si A es el número de años que vivirá un paciente que toma Arimidex y T es el número de años que vivirá un paciente que toma tamoxifeno, entonces la hipótesis que se está probando se puede escribir como A>T.
Definición. Una hipótesis se llama bilateral si consiste en la igualdad de dos cantidades.
Un ejemplo de hipótesis bilateral: A=T.
Definición. Una hipótesis se llama unilateral (unilateral) si consiste en la desigualdad de dos cantidades.
Ejemplos de hipótesis unilaterales:
Datos dicotómicos (binarios)
Definición. Datos expresados por sólo dos valores alternativos válidos
Ejemplo: El paciente está “sano” - “enfermo”. Edema "es" - "no".
Intervalo de confianza
Definición. El intervalo de confianza para una cantidad es el rango alrededor del valor de la cantidad en el que se encuentra el valor real de esa cantidad (con un cierto nivel de confianza).
Ejemplo. Sea la cantidad en estudio el número de pacientes por año. En promedio, su número es 500, y el 95% - intervalo de confianza- (350, 900). Esto significa que, lo más probable (con una probabilidad del 95%), al menos 350 y no más de 900 personas se comunicarán con la clínica durante el año.
Designación. Una abreviatura muy utilizada es: IC 95% es un intervalo de confianza con un nivel de confianza del 95%.
Fiabilidad, significación estadística (nivel P)
Definición. La significación estadística de un resultado es una medida de confianza en su "verdad".
Cualquier investigación se lleva a cabo basándose sólo en una parte de los objetos. El estudio de la eficacia de un fármaco no se lleva a cabo sobre la base de todos los pacientes del planeta, sino solo sobre un determinado grupo de pacientes (es simplemente imposible realizar un análisis sobre la base de todos los pacientes).
Supongamos que como resultado del análisis se llegó a una determinada conclusión (por ejemplo, el uso de Arimidex como terapia adecuada es 2 veces más eficaz que el tamoxifeno).
La pregunta que hay que hacerse es: “¿Cuánto se puede confiar en este resultado?”
Imaginemos que realizamos un estudio basado en sólo dos pacientes. Por supuesto, en este caso los resultados deben tomarse con cautela. Si se examinó a un gran número de pacientes (el valor numérico de un "gran número" depende de la situación), entonces ya se puede confiar en las conclusiones extraídas.
Entonces, el grado de confianza está determinado por el valor del nivel p (valor p).
Un nivel p más alto corresponde a un nivel más bajo de confianza en los resultados obtenidos del análisis de la muestra. Por ejemplo, un nivel p igual a 0,05 (5%) indica que la conclusión extraída del análisis de un determinado grupo es sólo una característica aleatoria de estos objetos con una probabilidad de sólo el 5%.
En otras palabras, con una probabilidad muy alta (95%) la conclusión se puede extender a todos los objetos.
Muchos estudios consideran que el 5% es un valor de nivel p aceptable. Esto significa que si, por ejemplo, p = 0,01, entonces se puede confiar en los resultados, pero si p = 0,06, entonces no se puede confiar.
Estudiar
estudio prospectivo Es un estudio en el que se seleccionan muestras en base a un factor inicial y se analiza algún factor resultante en las muestras.
Estudio retrospectivo Es un estudio en el que se seleccionan muestras en función de un factor resultante y se analiza algún factor inicial en las muestras.
Ejemplo. El factor inicial es una mujer embarazada menor/mayor de 20 años. El factor resultante es que el niño pesa menos o pesa más de 2,5 kg. Analizamos si el peso del niño depende de la edad de la madre.
Si reclutamos 2 muestras, una con madres menores de 20 años y la otra con madres mayores, y luego analizamos la masa de niños en cada grupo, entonces este es un estudio prospectivo.
Si reclutamos 2 muestras, en una, madres que dieron a luz a niños que pesaban menos de 2,5 kg, en la otra, más pesadas, y luego analizamos la edad de las madres en cada grupo, entonces este es un estudio retrospectivo (naturalmente, tal estudio sólo se puede llevar a cabo cuando se completa el experimento, es decir, cuando nacieron todos los niños).
éxodo
Definición. Un fenómeno, indicador de laboratorio o signo clínicamente significativo que sirve como objeto de interés para el investigador. Al realizar ensayos clínicos, los resultados sirven como criterio para evaluar la eficacia de una intervención terapéutica o preventiva.
Epidemiología clínica
Definición. Ciencia que permite predecir un resultado particular para cada paciente específico basándose en el estudio del curso clínico de la enfermedad en casos similares utilizando métodos científicos estrictos de estudio de los pacientes para garantizar la precisión de las predicciones.
Cohorte
Definición. Un grupo de participantes en un estudio unidos por alguna característica común en el momento de su formación y estudiados durante un largo período de tiempo.
Control
Control histórico
Definición. Se formó y examinó un grupo de control en el período anterior al estudio.
control paralelo
Definición. Se formó un grupo de control simultáneamente con la formación del grupo principal.
Correlación
Definición. Una relación estadística entre dos características (cuantitativa u ordinal), que muestra que un valor mayor de una característica en una determinada parte de los casos corresponde a un valor mayor - en el caso de una correlación positiva (directa) - de la otra característica o a un valor menor. valor - en el caso de una correlación negativa (inversa).
Ejemplo. Se encontró una correlación significativa entre los niveles de plaquetas y leucocitos en la sangre del paciente. El coeficiente de correlación es 0,76.
Coeficiente de riesgo (RR)
Definición. La razón de riesgo es la relación entre la probabilidad de que ocurra algún evento (“malo”) para el primer grupo de objetos y la probabilidad de que ocurra el mismo evento para el segundo grupo de objetos.
Ejemplo. Si la probabilidad de desarrollar cáncer de pulmón en los no fumadores es del 20% y en los fumadores del 100%, entonces la CR será igual a una quinta parte. En este ejemplo, el primer grupo de objetos son no fumadores, el segundo grupo son fumadores y la aparición de cáncer de pulmón se considera un evento "malo".
Es obvio que:
1) si KR = 1, entonces la probabilidad de que ocurra un evento en grupos es la misma
2) si KP>1, entonces el evento ocurre más a menudo con objetos del primer grupo que del segundo
3) si kr<1, то событие чаще происходит с объектами из второй группы, чем из первой
Metaanálisis
Definición. CON análisis estadístico que resume los resultados de varios estudios que investigan el mismo problema (generalmente la efectividad del tratamiento, la prevención, los métodos de diagnóstico). La agrupación de estudios proporciona una muestra más grande para el análisis y un mayor poder estadístico para los estudios combinados. Se utiliza para aumentar la evidencia o la confianza en una conclusión sobre la efectividad del método en estudio.
Método de Kaplan-Meier (estimaciones del multiplicador de Kaplan-Meier)
Este método fue inventado por los estadísticos E.L. Kaplan y Paul Meyer.
El método se utiliza para calcular varias cantidades asociadas con el tiempo de observación de un paciente. Ejemplos de tales cantidades:
probabilidad de recuperación dentro de un año cuando se usa el medicamento
probabilidad de recaída después de la cirugía dentro de los tres años posteriores a la cirugía
probabilidad acumulada de supervivencia a cinco años entre pacientes con cáncer de próstata después de la amputación de un órgano
Expliquemos las ventajas de utilizar el método Kaplan-Meier.
Los valores de los valores en el análisis "convencional" (sin utilizar el método de Kaplan-Meier) se calculan dividiendo el intervalo de tiempo considerado en intervalos.
Por ejemplo, si estudiamos la probabilidad de muerte de un paciente dentro de 5 años, entonces el intervalo de tiempo se puede dividir en 5 partes (menos de 1 año, 1-2 años, 2-3 años, 3-4 años, 4- 5 años), así y por 10 (seis meses cada uno), o por otro número de intervalos. Los resultados para diferentes particiones serán diferentes.
Elegir la partición más adecuada no es tarea fácil.
Las estimaciones de los valores obtenidos mediante el método de Kaplan-Meier no dependen de la división del tiempo de observación en intervalos, sino que dependen únicamente del tiempo de vida de cada paciente individual.
Por lo tanto, es más fácil para el investigador realizar el análisis y los resultados suelen ser mejores que los del análisis “convencional”.
La curva de Kaplan-Meier es una gráfica de la curva de supervivencia obtenida mediante el método de Kaplan-Meier.
modelo cox
Este modelo fue inventado por Sir David Roxby Cox (n. 1924), un famoso estadístico inglés, autor de más de 300 artículos y libros.
El modelo de Cox se utiliza en situaciones donde las cantidades estudiadas en el análisis de supervivencia dependen de funciones del tiempo. Por ejemplo, la probabilidad de recaída después de t años (t=1,2,...) puede depender del logaritmo del tiempo log(t).
Una ventaja importante del método propuesto por Cox es la aplicabilidad de este método en una gran cantidad de situaciones (el modelo no impone restricciones estrictas sobre la naturaleza o forma de la distribución de probabilidad).
A partir del modelo de Cox se puede realizar un análisis (llamado análisis de Cox), cuyo resultado es el valor del coeficiente de riesgo y el intervalo de confianza para el coeficiente de riesgo.
Métodos estadísticos no paramétricos.
Definición. Clase de métodos estadísticos que se utilizan principalmente para el análisis de datos cuantitativos que no forman una distribución normal, así como para el análisis de datos cualitativos.
Ejemplo. Para identificar la importancia de las diferencias en la presión sistólica de los pacientes según el tipo de tratamiento utilizaremos la prueba no paramétrica de Mann-Whitney.
Signo (variable)
Definición. incógnita características del objeto de estudio (observación). Hay características cualitativas y cuantitativas.
Aleatorización
Definición. Un método para distribuir aleatoriamente objetos de investigación en los grupos principal y de control utilizando medios especiales (tablas o contador de números aleatorios, lanzamiento de moneda y otros métodos para asignar aleatoriamente un número de grupo a una observación incluida). La aleatorización minimiza las diferencias entre grupos sobre características conocidas y desconocidas que potencialmente influyen en el resultado que se estudia.
Riesgo
Atributivo- riesgo adicional de un resultado desfavorable (por ejemplo, enfermedad) debido a la presencia de una determinada característica (factor de riesgo) en el tema del estudio. Esta es la porción del riesgo de desarrollar una enfermedad que está asociada, explicada y puede eliminarse si se elimina el factor de riesgo.
Riesgo relativo- la relación entre el riesgo de una condición desfavorable en un grupo y el riesgo de esta condición en otro grupo. Se utiliza en estudios prospectivos y observacionales cuando los grupos se forman con anticipación y aún no se ha producido la aparición de la condición en estudio.
examen continuo
Definición. Un método para verificar la estabilidad, confiabilidad y desempeño (validez) de un modelo estadístico eliminando secuencialmente observaciones y recalculando el modelo. Cuanto más similares sean los modelos resultantes, más estable y fiable será el modelo.
Evento
Definición. El resultado clínico observado en el estudio, como la aparición de una complicación, recaída, recuperación o muerte.
Estratificación
Definición. METRO una técnica de muestreo en la que la población de todos los participantes que cumplen con los criterios de inclusión para un estudio se divide primero en grupos (estratos) en función de una o más características (generalmente sexo, edad) que potencialmente influyen en el resultado de interés, y luego de cada una de Los participantes de estos grupos (estrato) se reclutan de forma independiente en los grupos experimental y de control. Esto permite al investigador equilibrar características importantes entre los grupos experimental y de control.
tabla de contingencia
Definición. Una tabla de frecuencias absolutas (números) de observaciones, cuyas columnas corresponden a los valores de una característica y las filas, a los valores de otra característica (en el caso de una tabla de contingencia bidimensional). Los valores de frecuencia absoluta se encuentran en celdas en la intersección de filas y columnas.
Pongamos un ejemplo de tabla de contingencia. La cirugía de aneurisma se realizó en 194 pacientes. Se conoce la gravedad del edema en pacientes antes de la cirugía.
|
Edema\ Resultado | |||
|---|---|---|---|
| sin hinchazón | 20 | 6 | 26 |
| hinchazón moderada | 27 | 15 | 42 |
| edema pronunciado | 8 | 21 | 29 |
| mj | 55 | 42 | 194 |
Así, de 26 pacientes sin edema, 20 sobrevivieron después de la cirugía y 6 pacientes murieron. De los 42 pacientes con edema moderado, 27 sobrevivieron, 15 murieron, etc.
Prueba de chi-cuadrado para tablas de contingencia
Para determinar la importancia (confiabilidad) de las diferencias en un signo dependiendo de otro (por ejemplo, el resultado de una operación dependiendo de la gravedad del edema), se utiliza la prueba de chi-cuadrado para tablas de contingencia:

Oportunidad
Sea la probabilidad de algún evento igual a p. Entonces la probabilidad de que el evento no ocurra es 1-p.
Por ejemplo, si la probabilidad de que un paciente siga vivo después de cinco años es de 0,8 (80%), entonces la probabilidad de que muera durante este período es de 0,2 (20%).
Definición. La probabilidad es la relación entre la probabilidad de que ocurra un evento y la probabilidad de que no ocurra.
Ejemplo. En nuestro ejemplo (sobre un paciente), la probabilidad es 4, ya que 0,8/0,2=4
Por tanto, la probabilidad de recuperación es 4 veces mayor que la probabilidad de muerte.
Interpretación del valor de una cantidad.
1) Si probabilidad = 1, entonces la probabilidad de que ocurra un evento es igual a la probabilidad de que el evento no ocurra;
2) si Probabilidad >1, entonces la probabilidad de que ocurra el evento es mayor que la probabilidad de que no ocurra;
3) si oportunidad<1, то вероятность наступления события меньше вероятности того, что событие не произойдёт.
Razón de probabilidades
Definición. La razón de probabilidades es la razón de probabilidades para el primer grupo de objetos con respecto a la razón de probabilidades para el segundo grupo de objetos.
Ejemplo. Supongamos que tanto hombres como mujeres se someten a algún tratamiento.
La probabilidad de que un paciente varón siga vivo después de cinco años es de 0,6 (60%); la probabilidad de que muera durante este período de tiempo es de 0,4 (40%).
Probabilidades similares para las mujeres son 0,8 y 0,2.
La razón de probabilidades en este ejemplo es
Interpretación del valor de una cantidad.
1) Si el odds ratio = 1, entonces la probabilidad para el primer grupo es igual a la probabilidad para el segundo grupo.
2) Si el odds ratio es >1, entonces la probabilidad para el primer grupo es mayor que la probabilidad para el segundo grupo.
3) Si la razón de probabilidades<1, то шанс для первой группы меньше шанса для второй группы
Más recientemente, Vladimir Davydov escribió una publicación en Facebook sobre las pruebas A/B o MVT, que generó muchas preguntas.
Normalmente, realizar pruebas A/B o MVT en sitios web es algo muy difícil. Aunque a los “landers” les parece que esto es elemental, porque “es lo mismo, hay programas especiales, eh”.
Si decides probar el contenido web, recuerda:
1. En primer lugar, es necesario aislar una audiencia de igual tamaño y calidad. Realizar pruebas A/A. La gran mayoría de las pruebas realizadas por agencias en línea o especialistas en marketing de Internet sin experiencia son incorrectas. Precisamente por el hecho de que el contenido se prueba en diferentes audiencias.
2. Realizar docenas o, mejor aún, cientos de pruebas durante varios meses. No vale la pena probar 2 o 3 versiones de una página durante una semana.
3. Recuerda que también puedes realizar pruebas en formato MVT (es decir, muchas opciones), y no solo A y B.
4. Analice estadísticamente la matriz de datos con los resultados de las pruebas (Excel está absolutamente bien, también puede usar SPSS). ¿Están los resultados dentro del margen de error, cuánto se desvían y cómo dependen del tiempo? Si, por ejemplo, en el primer punto de la prueba A/A recibió fuertes desviaciones de una opción respecto de otra, esto es un fracaso y no puede realizar más pruebas.
5. No es necesario probarlo todo. Esto no es entretenimiento (a menos que realmente no tengas nada más que hacer). Tiene sentido probar sólo lo que, desde el punto de vista del marketing y el análisis empresarial, puede conducir a resultados notables. Y también algo a partir de lo cual se puedan medir los resultados. Por ejemplo, decidió aumentar el tamaño de fuente en el sitio web, probó una página con una fuente más grande durante un par de semanas y las ventas aumentaron. ¿Qué quiere decir esto? Eso no es nada para mí (ver párrafos anteriores).
6. Es necesario probar caminos completos. Es decir, no basta con tomar y probar la página de compra (o alguna acción en el sitio); es necesario probar esas páginas y los pasos que conducen a esta página de conversión final.
La pregunta se hizo en los comentarios:
“¿Cómo determinar el ganador? Aquí probamos el título en una página que se vende "de frente". ¿Qué diferencia de conversión debe haber entre A y B para declarar ganador?
La respuesta de Vladimir:
En primer lugar, es necesario realizar experimentos aislados a largo plazo (la regla básica de cualquier evaluación estadística). En segundo lugar, todo se reduce inevitablemente a la estadística y las matemáticas (por eso recomiendo Excel y spss o análogos gratuitos. Necesitamos calcular la probabilidad de confianza de que la diferencia de valores signifique algo). Hay un buen artículo (uno de muchos). Allí toman transacciones de GA basándose en pruebas de Optimizelyhttps://www.distilled.net/uploads/ga_transactions.png , compare las transacciones (compras) con la distribución de campana habitual y vea si el valor promedio cae dentro del intervalo de confianza del errorhttps://www.distilled.net/uploads/t-test_tool.png
¿Le gustaría recibir una oferta nuestra?
Iniciar la cooperaciónEl papel de la importancia estadística en el aumento de las conversiones: 6 cosas que necesita saber
1. Exactamente lo que significa

"El cambio nos permitió lograr un aumento del 20 % en la conversión con un nivel de confianza del 90 %". Lamentablemente, esta afirmación no equivale en absoluto a otra muy similar: “Las posibilidades de aumentar la conversión en un 20% son del 90%”. Entonces, ¿de qué se trata realmente?
El 20% es un aumento que registramos según los resultados de las pruebas realizadas en una de las muestras. Si empezáramos a fantasear y especular, podríamos imaginar que este crecimiento podría persistir permanentemente, si continuáramos probando indefinidamente. Pero esto no significa que con un 90% de probabilidad obtendremos un aumento del veinte por ciento en la conversión, o un aumento de “al menos” un 20%, o “aproximadamente” un 20%.
El 90% es la probabilidad de cualquier cambio en la conversión. En otras palabras, si ejecutamos diez pruebas A/B para obtener este resultado y decidimos ejecutar las diez hasta el infinito, entonces una de ellas (dado que la probabilidad de cambio es del 90 %, entonces queda el 10 % para el resultado sin cambios) probablemente terminaría acercando el resultado de la “prueba posterior” a la conversión original, es decir, sin cambios. De las nueve pruebas restantes, algunas podrían mostrar un aumento muy inferior al 20%. En otros, el resultado podría superar este listón.
Si malinterpretamos estos datos, corremos un gran riesgo al “implementar” la prueba. Es fácil entusiasmarse cuando una prueba muestra altas tasas de conversión con un nivel de confianza del 95%, pero es aconsejable no esperar demasiado hasta que la prueba llegue a su conclusión lógica.
2. Cuándo utilizar
Los candidatos más obvios son las pruebas divididas A/B, pero están lejos de ser los únicos. También puede probar diferencias estadísticamente significativas entre segmentos (por ejemplo, visitas de búsqueda orgánica versus búsqueda paga) o períodos de tiempo (por ejemplo, abril de 2013 y abril de 2014).
Sin embargo, vale la pena señalar que esta correlación no implica causalidad. Cuando ejecutamos pruebas divididas, sabemos que podemos atribuir cualquier cambio en los resultados a los elementos que hacen que las páginas sean diferentes; prestamos especial atención a garantizar que, por lo demás, las páginas sean exactamente idénticas. Si compara grupos como los visitantes provenientes de la búsqueda orgánica y de pago, cualquier otro factor puede entrar en juego; por ejemplo, desde la búsqueda orgánica puede haber muchas visitas por la noche y la tasa de conversión entre los visitantes nocturnos es bastante alta. Las pruebas de significancia pueden ayudar a determinar si existe un motivo para un cambio, pero no pueden decir cuál es el motivo.
3. Cómo probar cambios en las tasas de conversión, tasas de rebote y tasas de salida
Cuando miramos los “indicadores”, en realidad estamos mirando promedios de variables binarias: alguien completó las acciones objetivo o no. Si tenemos una muestra de 10 personas con una tasa de conversión del 40%, en realidad estamos viendo una tabla como esta:

Necesitamos esta tabla, junto con el promedio, para calcular la desviación estándar, un componente clave de la significancia estadística. Sin embargo, el hecho de que cada valor en la tabla sea cero o uno nos lo hace más fácil: podemos evitar tener que copiar una lista enorme de números usando una calculadora de confianza de prueba A/B y comenzando por conocer el promedio. y tamaños de muestras. Esta es una herramienta de KissMetrics.

(¡Importante! Esta herramienta solo tiene en cuenta un lado de la distribución de probabilidad en sus cálculos. Para usar ambos lados y convertir el resultado a significación bilateral, debe duplicar la distancia desde el 100%; por ejemplo, unilateral 95 El % se vuelve bilateral 90%).
Aunque la descripción dice "Herramienta de validez de prueba A/B", también se puede utilizar para cualquier otra comparación de métricas: simplemente reemplace la conversión con la tasa de rebote o de salida. Además, se puede utilizar para comparar segmentos o períodos de tiempo; los cálculos serán los mismos.
También es muy adecuado para pruebas multivariadas (MVT): simplemente compare cada cambio individualmente con el original.
4. Cómo probar cambios en la factura promedio
Para probar las medias de variables no binarias, necesitamos el conjunto de datos completo, por lo que las cosas se complican un poco más aquí. Por ejemplo, queremos determinar si existe una diferencia significativa en el valor promedio del pedido para una prueba dividida A/B; este punto a menudo se omite en la optimización de la conversión, aunque para los indicadores comerciales es tan importante como la conversión misma.
Lo primero que necesitamos es obtener una lista completa de transacciones de Google Analytics para cada opción de prueba, para A y B (era, ahora). La forma más sencilla de hacerlo es crear segmentos personalizados basados en variables personalizadas para su prueba dividida y luego exportar el informe de transacciones a una hoja de cálculo de Excel. Asegúrese de que todas las transacciones estén incluidas allí, no solo las 10 filas predeterminadas.

Cuando tenga dos listas de transacciones, puede copiarlas en una herramienta como esta:
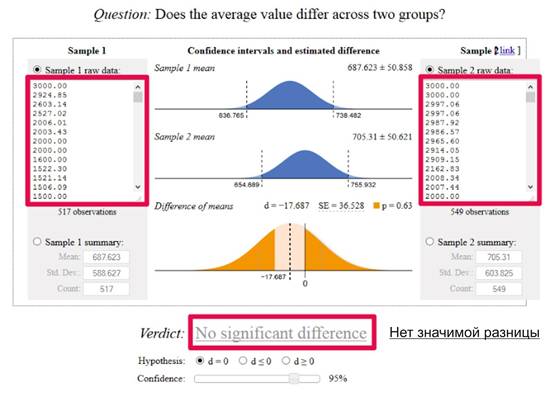
En el caso anterior, no tenemos un nivel de confianza en el nivel elegido del 95%. De hecho, si miramos la puntuación p encima del gráfico inferior de 0,63, está claro que ni siquiera tenemos un 50% de significancia: hay un 63% de posibilidades de que la diferencia entre las puntuaciones de las páginas se deba exclusivamente al azar.
5. Cómo predecir la duración requerida de una prueba dividida A/B
Evanmiller.org tiene otra herramienta útil para optimizar la conversión: una calculadora de tamaño de muestra.
Esta herramienta le permite responder a la pregunta “¿Cuánto tiempo llevará obtener resultados confiables de las pruebas?”, y no vale la pena intentar adivinar esta respuesta.

Hay algunas cosas que vale la pena señalar. Primero, la herramienta tiene un interruptor absoluto/relativo: si desea conocer la diferencia entre una tasa de conversión base del 5% y una tasa de conversión variable del 6%, será 1% absoluto (6-5=1) o 20 % en términos relativos (6/5=1,2). En segundo lugar, en la parte inferior de la página hay dos "controles deslizantes". El inferior es responsable del nivel de significancia requerido: si su objetivo es lograr una significancia del 95%, entonces el control deslizante debe establecerse en el 5%. El control deslizante superior muestra la probabilidad de que el número de visitas requeridas a una página sea suficiente; por ejemplo, si desea saber el número de visitas necesarias para lograr un ochenta por ciento de posibilidades de encontrar una significancia del 95 %, establezca el control deslizante superior en 80% y el control deslizante inferior al 5%.
6. Qué no hacer
Hay varias formas sencillas de identificar la inadecuación de una prueba dividida, que, sin embargo, no siempre son obvias a primera vista:
A) Prueba dividida de valores ordinales no binarios
Por ejemplo, su objetivo es determinar si existe una diferencia significativa en la probabilidad de que los visitantes de los grupos originales y posteriores al cambio compren ciertos productos. Usted etiqueta los tres productos como "1", "2" y "3" y luego ingresa estos valores en los campos de prueba de significancia. Desafortunadamente, este enfoque no funcionará: el producto 2 no es el promedio de los productos 1 y 3.
B) Configuración de distribución del tráfico

Al comienzo de la prueba, decides no correr riesgos y estableces la distribución del tráfico en 90/10. Después de un tiempo, verá que el cambio no provocó un cambio notable en la conversión y moverá el control deslizante a 50/50. Pero los visitantes que regresan aún pertenecen a su grupo original, por lo que terminas en una situación en la que la versión "previa al cambio" tiene una mayor proporción de visitantes que regresan y muestran una alta probabilidad de realizar una conversión. Las cosas se complican muy rápidamente y la única forma sencilla de obtener datos en los que pueda confiar es observar a los visitantes nuevos y recurrentes por separado. Sin embargo, en este caso llevará más tiempo obtener resultados significativos. E incluso si ambos subgrupos muestran resultados significativos, ¿qué pasa si uno de ellos realmente genera más visitantes que regresan? En general, no es necesario hacer esto y cambiar la distribución del tráfico durante la prueba.
B) Planificación
Parece obvio, pero no compare los datos recopilados a la misma hora del día con los datos recopilados durante el día o en otros momentos del día. Si desea realizar la prueba para una hora específica del día, tiene dos opciones.
1. Maneje las solicitudes de los visitantes a lo largo del día como de costumbre, pero muéstreles la versión original de la página en un momento del día que no le interese.
2. Compare manzanas con manzanas: si solo está viendo los datos de cambios de la primera mitad del día, compárelos con los datos originales de la primera mitad del día.
Espero que algo de lo anterior le resulte útil para optimizar sus tasas de conversión. Si tiene sus propios conocimientos, compártalos en los comentarios.
¿Qué crees que hace que tu “otra mitad” sea especial y significativa? ¿Está relacionado con su personalidad o con los sentimientos que tienes por esta persona? ¿O tal vez con el simple hecho de que la hipótesis sobre la aleatoriedad de tu simpatía, como muestran los estudios, tiene una probabilidad inferior al 5%? Si consideramos fiable la última afirmación, entonces, en principio, no existirían sitios de citas exitosos:
Cuando realiza pruebas divididas o cualquier otro análisis de su sitio web, malinterpretar la "significancia estadística" puede llevar a una mala interpretación de los resultados y, por lo tanto, a acciones incorrectas en el proceso de optimización de la conversión. Esto es cierto para las miles de otras pruebas estadísticas que se realizan todos los días en todas las industrias existentes.
Para descubrir qué es " significancia estadística“, necesita sumergirse en la historia de la aparición de este término, conocer su verdadero significado y comprender cómo esta “nueva” y antigua comprensión le ayudará a interpretar correctamente los resultados de su investigación.
un poco de historia
Aunque la humanidad ha estado utilizando las estadísticas para resolver diversos problemas durante muchos siglos, la comprensión moderna de la significación estadística, la prueba de hipótesis, la aleatorización e incluso el Diseño de Experimentos (DOE) comenzó a tomar forma recién a principios del siglo XX y está indisolublemente ligada a el nombre de Sir Ronald Fisher (Sir Ronald Fisher, 1890-1962):

Ronald Fisher fue un biólogo y estadístico evolutivo que tenía una pasión especial por el estudio de la evolución y la selección natural en los reinos animal y vegetal. Durante su ilustre carrera, desarrolló y popularizó muchas herramientas estadísticas útiles que todavía utilizamos hoy.
Fisher utilizó las técnicas que desarrolló para explicar procesos biológicos como la dominancia, las mutaciones y las desviaciones genéticas. Podemos utilizar las mismas herramientas hoy para optimizar y mejorar el contenido de los recursos web. El hecho de que estas herramientas de análisis puedan usarse para trabajar con objetos que ni siquiera existían en el momento de su creación parece bastante sorprendente. Es igualmente sorprendente que la gente solía realizar cálculos complejos sin calculadoras ni ordenadores.
Para describir los resultados de un experimento estadístico como si tuvieran una alta probabilidad de ser ciertos, Fisher utilizó la palabra "significancia".
Además, uno de los desarrollos más interesantes de Fisher puede denominarse la hipótesis del "hijo sexy". Según esta teoría, las mujeres prefieren a los hombres sexualmente promiscuos (promiscuos) porque esto permitirá que los hijos nacidos de estos hombres tengan la misma predisposición y produzcan más descendencia (tenga en cuenta que esto es solo una teoría).
Pero nadie, ni siquiera los científicos brillantes, está inmune a cometer errores. Los defectos de Fisher todavía atormentan a los especialistas hasta el día de hoy. Pero recuerde las palabras de Albert Einstein: "Quien nunca ha cometido un error nunca ha creado nada nuevo".
Antes de pasar al siguiente punto, recuerde: la significación estadística se produce cuando la diferencia en los resultados de las pruebas es tan grande que no puede explicarse mediante factores aleatorios.
¿Cuál es tu hipótesis?
Para comprender lo que significa "significancia estadística", primero es necesario comprender qué es la "prueba de hipótesis", ya que los dos términos están estrechamente entrelazados.
Una hipótesis es sólo una teoría. Una vez que haya desarrollado una teoría, necesitará establecer un proceso para recolectar suficiente evidencia y recolectar realmente esa evidencia. Hay dos tipos de hipótesis.

Manzanas o naranjas, ¿cuál es mejor?
Hipótesis nula
Por regla general, aquí es donde muchas personas experimentan dificultades. Una cosa a tener en cuenta es que una hipótesis nula no es algo que deba probarse, como, por ejemplo, demostrar que un determinado cambio en un sitio web conducirá a un aumento en las conversiones, sino viceversa. La hipótesis nula es una teoría que afirma que si realiza algún cambio en el sitio, no sucederá nada. Y el objetivo del investigador es refutar esta teoría, no probarla.
Si nos fijamos en la experiencia de la resolución de crímenes, donde los investigadores también formulan hipótesis sobre quién es el criminal, la hipótesis nula toma la forma de la llamada presunción de inocencia, el concepto según el cual se presume inocente al acusado hasta que se demuestre su culpabilidad. en un tribunal de justicia.
Si la hipótesis nula es que dos objetos son iguales en sus propiedades y estás tratando de demostrar que uno es mejor (por ejemplo, A es mejor que B), debes rechazar la hipótesis nula en favor de la alternativa. Por ejemplo, está comparando una u otra herramienta de optimización de conversiones. En la hipótesis nula, ambos tienen el mismo efecto (o ningún efecto) sobre el objetivo. Como alternativa, el efecto de uno de ellos es mejor.
Su hipótesis alternativa puede contener un valor numérico, como B - A > 20%. En este caso, la hipótesis nula y la alternativa pueden tomar la siguiente forma:

Otro nombre para una hipótesis alternativa es hipótesis de investigación porque el investigador siempre está interesado en probar esta hipótesis en particular.
Significancia estadística y valor p.
Volvamos nuevamente a Ronald Fisher y su concepto de significación estadística.
Ahora que tienes una hipótesis nula y una alternativa, ¿cómo puedes probar una y refutar la otra?
Dado que la estadística, por su propia naturaleza, implica el estudio de una población específica (muestra), nunca se puede estar 100% seguro de los resultados obtenidos. Un buen ejemplo: los resultados electorales a menudo difieren de los resultados de las encuestas preliminares e incluso de los resultados de las encuestas a boca de urna.
El Dr. Fisher quería crear una línea divisoria que le permitiera saber si su experimento fue un éxito o no. Así apareció el índice de confiabilidad. La credibilidad es el nivel que tomamos para decir lo que consideramos “significativo” y lo que no. Si "p", el índice de significancia, es 0,05 o menos, entonces los resultados son fiables.
No te preocupes, en realidad no es tan confuso como parece.

Distribución de probabilidad gaussiana. A lo largo de los bordes están los valores menos probables de la variable, en el centro están los más probables. La puntuación P (área sombreada en verde) es la probabilidad de que el resultado observado ocurra por casualidad.
La distribución de probabilidad normal (distribución gaussiana) es una representación de todos valores posibles una determinada variable en el gráfico (en la figura anterior) y sus frecuencias. Si investiga correctamente y luego traza todas sus respuestas en un gráfico, obtendrá exactamente esta distribución. Según la distribución normal, recibirá un gran porcentaje de respuestas similares y el resto de opciones se ubicarán en los bordes del gráfico (las llamadas "colas"). Esta distribución de valores se encuentra a menudo en la naturaleza, por eso se la denomina “normal”.
Usando una ecuación basada en su muestra y los resultados de la prueba, puede calcular lo que se llama una "estadística de prueba", que indicará cuánto se desvían sus resultados. También le dirá qué tan cerca está de que la hipótesis nula sea cierta.
Para ayudarle a entenderlo, utilice calculadoras en línea para calcular la significación estadística:

Un ejemplo de este tipo de calculadoras.
La letra "p" representa la probabilidad de que la hipótesis nula sea cierta. Si el número es pequeño, indicará una diferencia entre los grupos de prueba, mientras que la hipótesis nula sería que son iguales. Gráficamente, parecerá que la estadística de su prueba estará más cerca de una de las colas de su distribución en forma de campana.
El Dr. Fisher decidió establecer el umbral de significancia en p ≤ 0,05. Sin embargo, esta afirmación es controvertida, ya que conduce a dos dificultades:
1. Primero, el hecho de que haya demostrado que la hipótesis nula es falsa no significa que haya demostrado la hipótesis alternativa. Todo este significado simplemente significa que no se puede probar ni A ni B.
2. En segundo lugar, si la puntuación p es 0,049, significará que la probabilidad de la hipótesis nula será del 4,9%. Esto puede significar que los resultados de su prueba pueden ser verdaderos y falsos al mismo tiempo.
Puede utilizar o no el puntaje p, pero luego deberá calcular la probabilidad de la hipótesis nula caso por caso y decidir si es lo suficientemente grande como para impedirle realizar los cambios que planeó y probó. .
El escenario más común para realizar una prueba estadística hoy en día es establecer un umbral de significancia de p ≤ 0,05 antes de ejecutar la prueba en sí. Solo asegúrese de observar de cerca el valor p cuando verifique sus resultados.
Errores 1 y 2
Ha pasado tanto tiempo que los errores que pueden ocurrir al utilizar la métrica de significancia estadística incluso han recibido nombres propios.
Errores tipo 1
Como se mencionó anteriormente, un valor p de 0,05 significa que hay un 5% de posibilidades de que la hipótesis nula sea cierta. Si no lo hace, cometerá el error número 1. Los resultados dicen que su nuevo sitio web aumentó sus tasas de conversión, pero hay un 5% de posibilidades de que no sea así.
Errores tipo 2
Este error es el opuesto al error 1: se acepta la hipótesis nula cuando es falsa. Por ejemplo, los resultados de las pruebas le indican que los cambios realizados en el sitio no aportaron ninguna mejora, aunque sí hubo cambios. Como resultado, pierde la oportunidad de mejorar su desempeño.
Este error es común en pruebas con un tamaño de muestra insuficiente, así que recuerde: cuanto mayor sea la muestra, más confiable será el resultado.
Conclusión
Quizás ningún término sea tan popular entre los investigadores como significación estadística. Cuando los resultados de las pruebas no son estadísticamente significativos, las consecuencias van desde un aumento en las tasas de conversión hasta el colapso de una empresa.
Y dado que los especialistas en marketing utilizan este término cuando optimizan sus recursos, es necesario saber qué significa realmente. Las condiciones de la prueba pueden variar, pero el tamaño de la muestra y los criterios de éxito siempre son importantes. Recuerda esto.
Las principales características de cualquier relación entre variables.
Dos de los más propiedades simples dependencias entre variables: (a) la magnitud de la relación y (b) la confiabilidad de la relación.
- Magnitud . La magnitud de la dependencia es más fácil de entender y medir que la confiabilidad. Por ejemplo, si algún hombre de la muestra tenía un valor de recuento de glóbulos blancos (WCC) superior al de cualquier mujer, entonces se puede decir que la relación entre las dos variables (Género y WCC) es muy alta. En otras palabras, podrías predecir los valores de una variable a partir de los valores de otra.
- Fiabilidad ("verdad"). La confiabilidad de la interdependencia es un concepto menos intuitivo que la magnitud de la dependencia, pero es extremadamente importante. La confiabilidad de la relación está directamente relacionada con la representatividad de una determinada muestra a partir de la cual se extraen conclusiones. En otras palabras, la confiabilidad se refiere a la probabilidad de que una relación sea redescubierta (en otras palabras, confirmada) utilizando datos de otra muestra extraída de la misma población.
Cabe recordar que el objetivo final casi nunca es estudiar esta muestra particular de valores; una muestra sólo es de interés en la medida en que proporciona información sobre toda la población. Si el estudio satisface ciertos criterios específicos, entonces la confiabilidad de las relaciones encontradas entre las variables de la muestra se puede cuantificar y presentar utilizando una medida estadística estándar.
La magnitud de la dependencia y la confiabilidad representan dos características diferentes de las dependencias entre variables. Sin embargo, no se puede decir que sean completamente independientes. Cuanto mayor sea la magnitud de la relación (conexión) entre variables en una muestra de tamaño normal, más confiable será (ver la siguiente sección).
La significancia estadística de un resultado (nivel p) es una medida estimada de confianza en su “verdad” (en el sentido de “representatividad de la muestra”). Más técnicamente hablando, el nivel p es una medida que varía en orden de magnitud decreciente con la confiabilidad del resultado. Más alto nivel p Corresponde a un menor nivel de confianza en la relación entre las variables encontradas en la muestra. Es decir, el nivel p representa la probabilidad de error asociada con la distribución del resultado observado a toda la población.
Por ejemplo, nivel p = 0,05(es decir, 1/20) indica que hay un 5% de posibilidades de que la relación entre las variables encontradas en la muestra sea solo una característica aleatoria de la muestra. En muchos estudios, un nivel p de 0,05 se considera un "margen aceptable" para el nivel de error.
No hay forma de evitar la arbitrariedad a la hora de decidir qué nivel de significancia debería considerarse realmente "significativo". La elección de un cierto nivel de significancia por encima del cual los resultados se rechazan como falsos es bastante arbitraria.
En la práctica, la decisión final generalmente depende de si el resultado fue predicho a priori (es decir, antes de realizar el experimento) o descubierto a posteriori como resultado de muchos análisis y comparaciones realizadas sobre una variedad de datos, así como sobre la tradición del campo de estudio.
Normalmente, en muchos campos, un resultado de p .05 es límite aceptable significación estadística, pero recuerde que este nivel todavía incluye una tasa de error bastante grande (5%).
Los resultados significativos al nivel de p 0,01 generalmente se consideran estadísticamente significativos, mientras que los resultados al nivel de p 0,005 o p 0,00 generalmente se consideran estadísticamente significativos. 001 como muy significativo. Sin embargo, debe entenderse que esta clasificación de niveles de significancia es bastante arbitraria y es sólo un acuerdo informal adoptado sobre la base experiencia practica en un campo de estudio particular.
Está claro que lo que numero mayor Cuanto más se realicen análisis sobre la totalidad de los datos recopilados, mayor será el número de resultados significativos (en el nivel seleccionado) que se descubrirán puramente por casualidad.
Algunos métodos estadísticos que implican muchas comparaciones y, por lo tanto, tienen una probabilidad significativa de repetir este tipo de errores, hacen un ajuste o corrección especial para número total comparaciones. Sin embargo, muchos métodos estadísticos (especialmente los métodos simples de análisis de datos exploratorios) no ofrecen ninguna forma de resolver este problema.
Si la relación entre variables es “objetivamente” débil, entonces no hay otra forma de probar dicha relación excepto estudiar una muestra grande. Incluso si la muestra es perfectamente representativa, el efecto no será estadísticamente significativo si la muestra es pequeña. Del mismo modo, si una relación es “objetivamente” muy fuerte, entonces puede detectarse con un alto grado de significancia incluso en una muestra muy pequeña.
Cuanto más débil sea la relación entre las variables, mayor será el tamaño de muestra necesario para detectarla de manera significativa.
Muchos diferentes medidas de relación entre variables. La elección de una medida particular en un estudio particular depende del número de variables, las escalas de medición utilizadas, la naturaleza de las relaciones, etc.
Sin embargo, la mayoría de estas medidas están sujetas a principio general: Intentan estimar la dependencia observada comparándola con la "dependencia máxima concebible" entre las variables consideradas. Técnicamente hablando, la forma habitual de hacer este tipo de estimaciones es observar cómo varían los valores de las variables y luego calcular qué parte de la variación total presente puede explicarse por la presencia de una variación "común" ("conjunta") en dos (o más) variables.
La importancia depende principalmente del tamaño de la muestra. Como ya se explicó, en muestras muy grandes incluso las relaciones muy débiles entre variables serán significativas, mientras que en muestras pequeñas incluso las relaciones muy fuertes no son confiables.
Así, para determinar el nivel de significancia estadística, se necesita una función que represente la relación entre la “magnitud” y la “significancia” de la relación entre variables para cada tamaño de muestra.
Tal función indicaría exactamente “qué probabilidad hay de obtener una dependencia de un valor dado (o más) en una muestra de un tamaño dado, suponiendo que no existe tal dependencia en la población”. En otras palabras, esta función daría un nivel de significancia
(nivel p), y, por tanto, la probabilidad de rechazar erróneamente el supuesto de ausencia de esta dependencia en la población.
Esta hipótesis "alternativa" (que no existe relación en la población) suele denominarse hipótesis nula.
Sería ideal si la función que calcula la probabilidad de error fuera lineal y solo tuviera pendientes diferentes para diferentes tamaños de muestra. Lamentablemente, esta función es mucho más compleja y no siempre es exactamente igual. Sin embargo, en la mayoría de los casos su forma es conocida y puede usarse para determinar niveles de significancia en estudios de muestras de un tamaño determinado. La mayoría de estas funciones están asociadas con una clase de distribuciones llamadas normal .